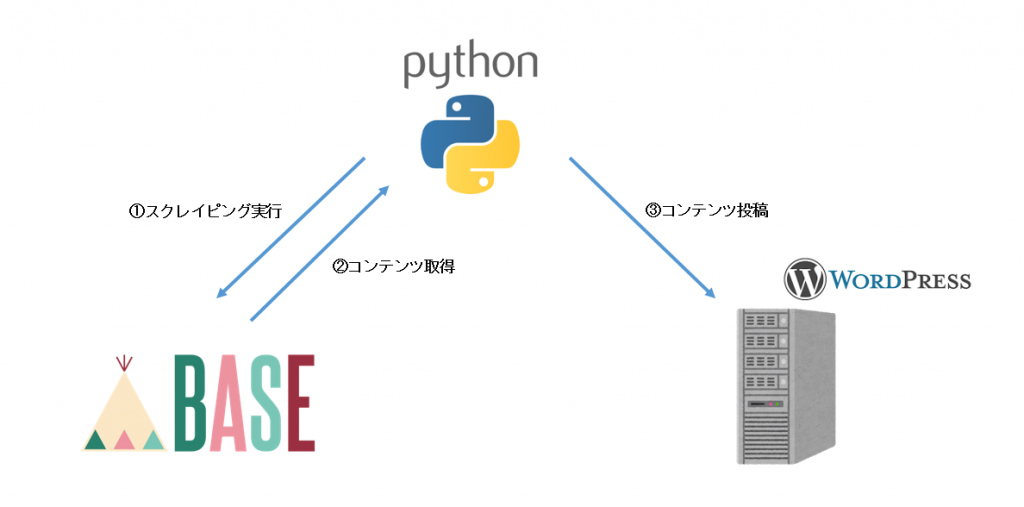
BASEのページをスクレイピングしてwordpressに投稿してみる

BASEのページをスクレイピングしてwordpressに投稿してみる
イメージ図
1.「beautifulsoup」を使用してBASEから情報を取得します
2.「BASEから取得した情報」をpythonで加工します
3.「paramiko」「wordpressAPI」を使用してwordpressに情報を送信し投稿します
階層
img:
・スクレイピングにより取得したイメージファイルを格納します。
minimalight.py:
・スクレイピングの対象となるページの情報を格納しています。
・cronなどで実際に実行されるファイルです。
scraping.py:
・実際にスクレイピングを行うファイルになります。
sftp.py:
・取得したイメージファイルをwordpressサーバーに送信します。
wordpress.py:
・取得した情報をワードプレスに投稿します。
.
├── img
│ ├── 00e5499cbd18fe3e4d7cb4490a73c888.jpg
│ ├── 1a0beae0397367930f57cf132025f704.jpg
│ ├── 29bdd42104bf3ee9428da5379b28fe94.jpg
│ ├── 6b4c9255243e9a77542a2a3053023b07.jpg
│ ├── 810f414a9c7123041ca73e150d24ab7a.jpg
│ ├── a278c60af1f0367cd5c7fac48c4dd279.jpg
│ ├── a8a38a74bb2606c4b90038c32d97c043.jpg
│ ├── ab38e9dd23ae22706db8729f78a43087.jpg
│ ├── acacf2dc3f734953d79f45e88519be2b.jpg
│ ├── b04c027dbc74e8a1f7031e1fbf2c733c.jpg
│ ├── be7164d9522dbfc338816502e31fbad6.jpg
│ ├── cf0cc92c28da49b1100e96f1705996a7.jpg
│ └── de26389ea26cbfc318e59ea644d18c8d.jpg
├── minimalight.py #実行用ファイル
└── module
├── scraping.py #スクレイピング用モジュール
├── sftp.py #ファイル送信用モジュール
└── wordpress.py #ワードプレス投稿用モジュール
実行用ファイル
このファイルを実行すると、スクレイピングする為のパラメータを配列で渡し「スクレイピング用モジュール」を実行します。
値を変える事でBASEの他のページもスクレイピングすることが可能です。
・config_dict['href'] のパラメータは常に最後に投稿されたhrefのパラメータが格納されます。
・config_dict['href'] のパラメータより後に投稿された商品を「新着の商品」とみなします。
・config_dict['href'] のパラメータは「sed」で書き換えています。
#config: utf-8
from module.scraping import activate
config_dict = {}
config_dict['url'] = 'https://minimalight.thebase.in/'
config_dict['href'] = 'https://minimalight.thebase.in/items/3446754'
config_dict['shop_name'] = 'minimalight'
config_dict['item_class_value'] = 'product_list'
config_dict['title_class_value'] = 'title'
config_dict['picture_class_value'] = 'image_container'
activate(config_dict)
スクレイピングモジュール
実行用ファイルから値を受け取りスクレイピングを実行します。
新着情報があれば「ファイル送信用モジュール」と「ワードプレス投稿用モジュール」を実行します。
#config: utf-8
import requests
import subprocess
from bs4 import BeautifulSoup
#mosules
from module.sftp import transfer_picture
from module.wordpress import post_content
def activate(config_dict):
request = requests.get(config_dict['url'])
soup = BeautifulSoup(request.content, 'html.parser')
items = get_items(soup, config_dict)
inspect_href(items, config_dict)
def get_items(soup, config_dict):
items = soup.find_all(class_ = config_dict['item_class_value'])
return items
def get_href(item, config_dict):
href = item.find('a').get('href')
return href
def get_item_name(item, config_dict):
title = item.find(class_ = config_dict['title_class_value']).string
return title
def get_picture(item, config_dict):
image_path = item.find('img').get('src')
request = requests.get(image_path)
with open('img/' + image_path.split('/')[-1],'wb') as file:
file.write(request.content)
picture = image_path.split('/')[-1]
return picture
def activate_sed(recent_href, config_dict):
#実行ファイルのhrefを書き換える
#「/」をエスケープする
recent_href = recent_href.replace('/','\/')
#「https://xxx/xxx/xxx」を「'https://xxx/xxx/xxx'」に変更する
recent_href = '\'' + recent_href + '\''
#sedで書き換え「[」と[']はエスケープする
subprocess.call(['sed','-i','-e','s/^config_dict\[\'href\'\].*/config_dict[\'href\'] = '+ recent_href + '/g','./'+ config_dict['shop_name']+'.py'])
def inspect_href(items, config_dict):
recent_href = config_dict['href']
href = ''
post_list = []
update_start = False
for item in reversed(items):
href = get_href(item, config_dict)
if update_start:
title = get_item_name(item, config_dict)
picture = get_picture(item, config_dict)
post_data = {}
post_data['shop_name'] = config_dict['shop_name']
post_data['url'] = config_dict['url']
post_data['href'] = href
post_data['title'] = title
post_data['picture'] = picture
print('ADD_LIS :' + href)
post_list.append(post_data)
recent_href = href
continue
if recent_href == href:
print('FOUND :' + href)
update_start = True
else:
print('DIFFERENT:' + href)
if post_list:
print('START_POST')
activate_sed(recent_href, config_dict)
transfer_picture(post_list)
post_content(post_list)
else:
print('NOTHING_TO_DO')
#該当するhrefが見つからなかった場合でも次回スクレイピングの為にrecent_hrefを最新のhrefに書き換えておく
recent_href = href
activate_sed(recent_href, config_dict)
ファイル送信用モジュール
スクレイピングで保存された「imgファイル」を「wordpressサーバー」に送信します。
#config: utf-8
import paramiko
HOST = 'xxx.xxx.xxx.xxx'
USER = 'username'
PSWD = 'password'
def transfer_picture(post_list):
ssh = paramiko.SSHClient()
ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy())
ssh.connect(HOST, username = USER, password = PSWD)
sftp = ssh.open_sftp()
for post_data in post_list:
LOCAL_PATH = '/xxx/yyy/zzz/img/' + post_data['picture']
REMOTE_PATH = '/xxx/yyy/zzz/transfered/' + post_data['picture']
sftp.put(LOCAL_PATH,REMOTE_PATH)
sftp.close()
ssh.close()
ワードプレス投稿用モジュール
ワードプレスに投稿するHTMLファイルを作成しています。
本文に「画像」と「ボタン」を設置しています。
「ボタン」に「href」を指定しているのでクリックすると本家「BASE」のサイトに飛ぶようになっています。
#config: utf-8
from wordpress_xmlrpc import Client, WordPressPost
from wordpress_xmlrpc.methods.posts import GetPosts, NewPost
from wordpress_xmlrpc.methods.users import GetUserInfo
from datetime import datetime
wp = Client('http://xxx/yyy/xmlrpc.php','username','password')
post = WordPressPost()
button_path_top = "Click Me"
picture_path_top = " "
def post_content(post_list):
for post_data in post_list:
post.title = post_data['title'].encode('utf-8')
post.content = picture_path_top + post_data['picture'] + picture_path_end + "
"
def post_content(post_list):
for post_data in post_list:
post.title = post_data['title'].encode('utf-8')
post.content = picture_path_top + post_data['picture'] + picture_path_end + "
" + button_path_top + post_data['href'] + button_path_end
post.terms_names = {'category': [post_data['shop_name']]}
post.post_status = 'publish'
wp.call(NewPost(post))
余談
プログラミングが楽しくてついついやってしまいますが、クラウドの勉強にも時間を取りたい今日この頃です。
時間がない時は「プログラミング」ある時は「クラウド」と時間をしっかりとっていこうと思います。
クラウドもアプリもデータ分析もやってみたいですが一歩ずつ...
追記
今回ファイル転送に「paramiko」を使用しましたが「wordpressAPI」でも可能みたいです。
pythonからWordPressに投稿&画像のアップロード